Edge Intelligence: Architectures, Challenges, and Applications
【文献精读】边缘智能:架构、挑战和应用
这篇关于边缘智能的综述文章最近一次修订时间为2020年12月。这篇文章的作者将边缘智能的相关工作分为四大部分:边缘缓存、边缘训练、边缘推断、边缘卸载,并且针对每部分研究工作进行了深入的文献调研和阐述分析。
Abstract
Edge intelligence refers to a set of connected systems and devices for data collection, caching, processing, and analysis proximity to where data is captured based on artificial intelligence. Edge intelligence aims at enhancing data processing and protect the privacy and security of the data and users. Although recently emerged, spanning the period from 2011 to now, this field of research has shown explosive growth over the past five years. In this paper, we present a thorough and comprehensive survey on the literature surrounding edge intelligence. We first identify four fundamental components of edge intelligence, i.e. edge caching, edge training, edge inference, and edge offloading based on theoretical and practical results pertaining to proposed and deployed systems. We then aim for a systematic classification of the state of the solutions by examining research results and observations for each of the four components and present a taxonomy that includes practical problems, adopted techniques, and application goals. For each category, we elaborate, compare and analyse the literature from the perspectives of adopted techniques, objectives, performance, advantages and drawbacks, etc. This article provides a comprehensive survey to edge intelligence and its application areas. In addition, we summarise the development of the emerging research fields and the current stateof-the-art and discuss the important open issues and possible theoretical and technical directions.
作者在摘要中首先指出了边缘智能的四个基本组成部分:边缘缓存、边缘训练、边缘推断、边缘卸载;然后对这四部分的研究成果进行系统分类,从采用的技术、目标、性能、优点和缺点等角度对文献进行阐述、比较和分析;最后总结了新兴研究领域的发展和当前的技术水平,并讨论了重要的开放问题和可能的理论和技术方向。
I. Introduction
With the breakthrough of Artificial Intelligence (AI), we are witnessing a booming increase in AI-based applications and services.
However, existing intelligent applications are computationintensive, which present strict requirements on resources, e.g., CPU, GPU, memory, and network, which makes it impossible to be available anytime and anywhere for end users. Although current end devices are increasingly powerful, it is still insufficient to support some deep learning models.
Moreover, existing intelligent applications generally adopt centralised data management, which requires users to upload their data to central cloud based data-centre.
However, there is giant volume of data which has been generated and collected by billions of mobile users and Internet of Thing (IoT) devices distributed at the network edge. Uploading such volume of data to the cloud consumes significant bandwidth resources, which would also result in unacceptable latency for users.
On the other hand, users increasingly concern their privacy. If mobile users upload their personal data to the cloud for a specific intelligent application, they would take the risk of privacy leakage, i.e., the personal data might be extracted by malicious hackers or companies for illegal purposes.
作者首先指出了研究的背景:人工智能应用和服务的飞速发展。但是,这些智能应用和服务存在一些问题,归结起来主要是以下三点:
- 终端计算资源不足:现有的智能应用程序是计算密集型的,对资源提出了严格的要求。虽然目前的终端设备越来越强大,但仍然不足以支持一些深度学习模型。
- 集中式云计算架构高时延:现有的智能应用程序通常采用集中式数据管理,这要求用户将其数据上传到基于云的中央数据中心。然而,网络边缘的用户数量十分庞大,将如此大量的数据上传到云中会消耗大量的带宽资源,这也将导致用户无法接受的延迟。
- 用户隐私安全问题:如果移动用户将他们的个人数据上传到云上用于特定的智能应用,他们将承担隐私泄露的风险。
The main advantages of the edge computing paradigm could be summarised into three aspects. (i) Ultra-low latency: computation usually takes place in the proximity of the source data, which saves substantial amounts of time on data transmission. Edge servers provides nearly real-time responses to end devices. (ii) Saving energy for end devices: since end devices could offload computing tasks to edge servers, the energy consumption on end devices would significantly shrink. Consequently, the battery life of end devices would be extended. (iii) Scalability: cloud computing is still available if there are no enough resource on edge devices or edge servers. In such a case, the cloud server would help to perform tasks. In addition, end devices with idle resources could communicate amongst themselves to collaboratively finish a task. The capability of the edge computing paradigm is flexible to accommodate different application scenarios.
因此,接下来作者顺理成章地提出了边缘计算的概念。作者首先阐述了边缘计算范式的三点优势:
- 超低延迟:计算通常在源数据附近进行,这节省了大量数据传输时间。
- 为终端设备节省能源:由于终端设备可以将计算任务卸载到边缘服务器,终端设备上的能耗将大幅减少。
- 可扩展性:如果边缘设备或边缘服务器上没有足够的资源,云计算仍然可用。在这种情况下,云服务器将有助于执行任务。此外,拥有空闲资源的终端设备可以相互通信,以协作方式完成任务。边缘计算范式的能力是灵活的,以适应不同的应用场景。
Edge computing addresses the critical challenges of AI based applications and the combination of edge computing and AI provides a promising solution. This new paradigm of intelligence is called edge intelligence, also named mobile intelligence.
边缘计算解决了基于人工智能的应用程序的关键挑战,边缘计算和人工智能的结合提供了一个有前途的解决方案。这种新的智能范式被称为边缘智能,也称为移动智能。
It is also worth noting that AI could also be a powerful assistance for edge computing. This paradigm is called intelligent edge, which is different from edge intelligence. The emphasis of edge intelligence is to realize intelligent applications in edge environment with the assistance of edge computing and protect users’ privacy, while intelligent edge focuses on solving problems of edge computing with AI solutions, e.g., resource allocation optimization. Intelligent edge is out of our scope in this survey.
同样值得注意的是,人工智能也可以成为边缘计算的有力辅助。这种范式称为智能边缘,不同于边缘智能。边缘智能的重点是借助边缘计算在边缘环境中实现智能应用,保护用户隐私,而智能边缘则侧重于用AI解决方案解决边缘计算的问题,例如资源分配优化。智能边缘并不在作者的调研范围内。
This paper aims at providing a comprehensive survey to the development and the state-of-the-art of edge intelligence.
本文旨在对边缘智能的发展和现状进行全面综述。这方面已有很多相关工作,作者在介绍中主要提到了以下几个方面:
- (边缘环境下的)联邦学习
- 边缘智能深度学习模型训练与推理(包括模型设计、模型压缩和模型加速等角度)
- 卸载策略和缓存策略
Our survey focuses on how to realise edge intelligence in a systematic way. There exist three key components in AI, i.e. data, model/algorithm, and computation. A complete process of implementing AI applications involves data collection and management, model training, and model inference. Computation plays an essential role throughout the whole process. Hence, we limit the scope of our survey on four aspects, including how to cache data to fuel intelligent applications (i.e., edge caching), how to train intelligent applications at the edge (i.e., edge training), how to infer intelligent applications at the edge (edge inference), and how to provide sufficient computing power for intelligent applications at the edge (edge offloading).
本文的调研侧重于如何以系统的方式实现边缘智能。人工智能有三个关键组成部分,即数据、模型/算法和计算。实现人工智能应用程序的完整过程包括数据收集和管理、模型训练和模型推理。计算在整个过程中起着重要的作用。因此,作者将调研范围限制在四个方面,包括如何缓存数据以支持智能应用(即边缘缓存),如何在边缘训练智能应用(即边缘训练),如何在边缘推断智能应用(边缘推断),以及如何在边缘为智能应用提供足够的计算能力(边缘卸载)。
Our contributions are summarized as following:
- We survey recent research achievements on edge intelligence and identify four key components: edge caching, edge training, edge inference, and edge offloading. For each component, we outline a systematical and comprehensive classification from a multi-dimensional view, e.g., practical challenges, solutions, optimisation goals, etc.
- We present thorough discussion and analysis on relevant papers in the field of edge intelligence from multiple views, e.g., applicable scenarios, methodology, performance, etc. and summarise their advantages and shortcomings.
- We discuss and summarise open issues and challenges in the implementation of edge intelligence, and outline five important future research directions and development trends, i.e., data scarcity, data consistency, adaptability of model/algorithms, privacy and security, and incentive mechanisms.
本文的贡献总结如下:
- 作者调研了边缘智能的最新研究成果,并确定了四个关键的组成部分:边缘缓存、边缘训练、边缘推理和边缘卸载。对于每个部分,作者从多个维度概述了一个系统和全面的分类,例如,实际挑战、解决方案、优化目标等。
- 作者从应用场景、方法论、性能等多个角度对边缘智能领域的相关论文进行了深入的讨论和分析。并总结它们的优点和缺点。
- 作者讨论和总结了边缘智能实现中的开放问题和挑战,并概述了五个重要的未来研究方向和发展趋势,即数据稀缺性、数据一致性、模型/算法的适应性、隐私和安全以及激励机制。
II. Overview
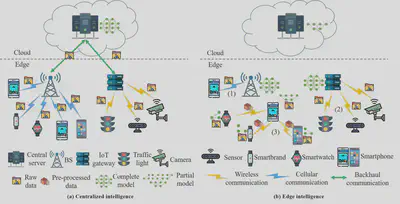
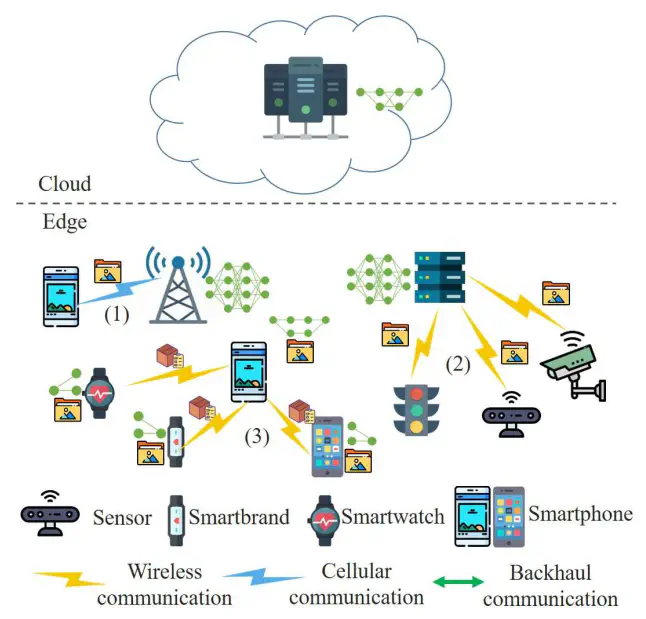
The comparison of traditional intelligence and edge intelligence from the perspective of implementation. In traditional intelligence, all data must be uploaded to a central cloud server, whilst in edge intelligence, intelligent application tasks are done at the edge with locally-generated data in a distributed manner.
作者从实现的角度比较了传统智能和边缘智能。在传统智能中,所有数据都必须上传到中央云服务器,而在边缘智能中,智能应用任务是在边缘以分布式方式使用本地生成的数据完成的。
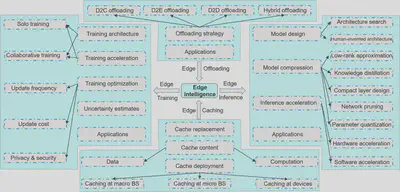
作者将边缘智能的文献分类绘制成上面的图,下面作者将给出这些模块的概述:
A. Edge Caching
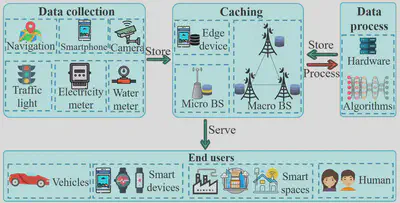
In edge intelligence, edge caching refers to a distributed data system proximity to end users, which collects and stores the data generated by edge devices and surrounding environments, and the data received from the Internet to support intelligent applications for users at the edge.
在边缘智能中,边缘缓存是指接近终端用户的分布式数据系统,它收集和存储边缘设备和周围环境生成的数据,以及从互联网接收的数据,以支持边缘用户的智能应用。
To implement edge caching, we answer three questions: (i) what to cache, (ii) where to cache, and (iii) how to cache.
为了实现边缘缓存,我们需要回答三个问题:
- 缓存什么
- 缓存到哪里
- 如何缓存
For the first problem, what to cache, we know that caching is based on the redundancy of requests. In edge caching, the collected data is inputted into intelligent applications and results are sent back to where data is cached. Hence, there are two kinds of redundancy: data redundancy and computation redundancy.
作者认为,在边缘缓存中,收集的数据被输入到智能应用程序中,结果被发送回缓存数据的地方。因此,有两种冗余:数据冗余和计算冗余。
Data redundancy, also named communication redundancy, means that the inputs of an intelligent application may be the same or partially the same. For example, in continuous mobile vision analysis, there are large amounts of similar pixels between consecutive frames. Some resourceconstrained edge devices need to upload collected videos to edge servers or the cloud for further processing. With cache, edge devices only needs to upload different pixels or frames. For the repeated part, edge devices could reuse the results to avoid unnecessary computation.
数据冗余,也称为通信冗余,意味着智能应用程序的输入可能相同或部分相同。例如,在连续移动视觉分析中,连续帧之间存在大量相似像素。一些资源受限的边缘设备需要将收集到的视频上传到边缘服务器或云端进行进一步处理。有了缓存,边缘设备只需要上传不同的像素或帧。对于重复的部分,边缘设备可以重用结果,以避免不必要的计算。
Caching based on such redundancy could effectively reduce computation and accelerate the inference. Computation redundancy means that the requested computing tasks of intelligent applications may be the same. For example, an edge server provides image recognition services for edge devices. The recognition tasks from the same context may be the same, e.g., the same tasks of flower recognition from different users of the same area. Edge servers could directly send the recognition results achieved previously back to users. Such kind of caching could significantly decrease computation and execution time.
基于这种冗余的缓存可以有效减少计算量,加快推理速度。计算冗余意味着智能应用程序所请求的计算任务可能是相同的。例如,边缘服务器为边缘设备提供图像识别服务。来自相同上下文的识别任务可以是相同的,例如来自相同区域的不同用户的花识别的相同任务。边缘服务器可以直接将之前获得的识别结果发送回用户。这种缓存可以显著减少计算和执行时间。
For the second problem, where to cache, existing works mainly focus on three places to deploy caches: macro BSs, micro BSs, and edge devices.
Since the storage capacity of macro BSs, micro BSs, and edge devices is limited, the content replacement must be considered. Works on this problem focus on designing replacement policies to maximise the service quality.
现有的工作主要集中在三个地方部署缓存:宏基站、微基站和边缘设备。由于宏基站、微基站和边缘设备的存储容量有限,因此必须考虑内容替换。关于这个问题的工作集中在设计替换策略以最大化服务质量。
B. Edge Training
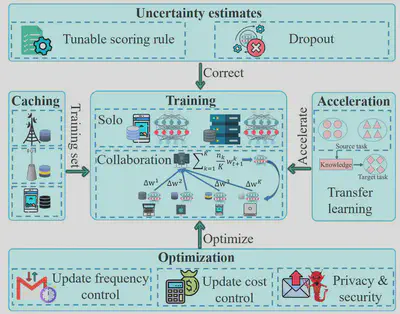
Edge training refers to a distributed learning procedure that learns the optimal values for all the weights and bias, or the hidden patterns based on the training set cached at the edge.
Different from traditional centralised training procedures on powerful servers or computing clusters, edge training usually occurs on edge servers or edge devices, which are usually not as powerful as centralised servers or computing clusters.
作者认为,边缘训练指的是一种分布式学习过程,它基于缓存在边缘的训练集来学习所有权重和偏差的最优值或隐藏模式。与传统的在功能强大的服务器或计算集群上的集中式训练过程不同,边缘训练通常发生在边缘服务器或边缘设备上,它们通常不如集中式服务器或计算集群强大。
Hence, in addition to the problem of training set (caching), four key problems should be considered for edge training: (i) how to train (the training architecture), (ii) how to make the training faster (acceleration), (iii) how to optimise the training procedure (optimisation), and (iv) how to estimate the uncertainty of the model output (uncertainty estimates).
因此,除了训练集(缓存)的问题之外,边缘训练还应考虑四个关键问题:
- 如何训练(训练架构)
- 如何使训练更快(加速)
- 如何优化训练过程(优化)
- 如何估计模型输出的不确定性(不确定性估计)
For the first problem, researchers design two training architectures: solo training and collaborative training. Solo training means training tasks are performed on a single device, without assistance from others, whilst collaborative training means that multiple devices cooperate to train a common model/algorithm. Since solo training has a higher requirement on the hardware, which is usually unavailable, most existing literature focuses on collaborative training architectures.
对于第一个问题,研究人员设计了两种训练架构:单独训练和协同训练。单独训练意味着在单个设备上执行训练任务,无需其他设备的帮助,而协同训练意味着多个设备协同训练一个公共模型/算法。由于单独训练对硬件有更高的要求,而这通常是不可用的,大多数现有的文献集中在协同训练体系结构上。
Different from centralised training paradigms, in which powerful CPUs and GPUs could guarantee a good result with a limited training time, edge training is much slower. Some researchers pay attention to the acceleration of edge training. Corresponding to training architecture, works on training acceleration are divided into two categories: acceleration for solo training, and collaborative training.
与集中式训练模式不同,在集中式训练模式中,强大的中央处理器和图形处理器可以在有限的训练时间内保证良好的结果,边缘训练要慢得多。一些研究者关注边缘训练的加速。与训练架构相对应,关于训练加速的工作分为两类:针对单独训练的加速,以及协同训练。
Solo training is a closed system, in which only iterative computation on single devices is needed to get the optimal parameters or patterns. In contrast, collaborative training is based on the cooperation of multiple devices, which requires periodic communication for updating. Update frequency and update cost are two factors which affect the performance of communication efficiency and training result. Researchers on this area mainly focus on how to maintain the performance of the model/algorithm with lower update frequency, and update cost. In addition, the public nature of collaborative training is vulnerable to malicious users. There is also some literature which focuses on the privacy and security issues.
单独训练是一个封闭的系统,只需要在单个设备上进行迭代计算就可以获得最佳的参数或模式。相比之下,协同训练是基于多个设备的协作,需要定期沟通进行更新。更新频率和更新成本是影响通信效率和训练效果的两个因素。该领域的研究人员主要关注如何在较低的更新频率下保持模型/算法的性能,以及更新成本。此外,协作培训的公共性容易受到恶意用户的攻击。还有一些文献关注隐私和安全问题。
In DL training, the output results may be erroneously interpreted as model confidence. Estimating uncertainty is easy on traditional intelligence, whilst it is resource-consuming for edge training. Some literature pays attention to this problem and proposes various kinds of solutions to reduce computation and energy consumption.
在深度学习训练中,输出结果可能会被错误地解释为模型置信度。对传统智能来说,估计不确定性是容易的,而对边缘训练来说则是耗费资源的。一些文献关注了这个问题,并提出了各种解决方案来减少计算和能耗。
C. Edge Inference
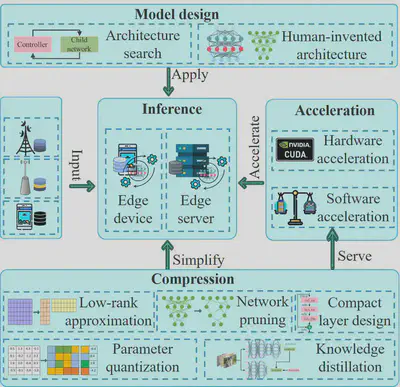
Edge inference is the stage where a trained model/algorithm is used to infer the testing instance by a forward pass to compute the output on edge devices and servers.
边缘推断是使用训练好的模型/算法通过向前传递来推断测试实例以计算边缘设备和服务器上的输出的阶段。
Most existing AI models are designed to be implemented on devices which have powerful CPUs and GPUs, this is not applicable in an edge environment. Hence, the critical problems of employing edge inference are: (i) how to make models applicable for their deployment on edge devices or servers (design new models, or compress existing models), and (ii) how to accelerate edge inference to provide real-time responses.
大多数现有的人工智能模型被设计成在具有强大的中央处理器和图形处理器的设备上实现,这不适用于边缘环境。因此,采用边缘推断的关键问题是:
- 如何使模型适用于它们在边缘设备或服务器上的部署(设计新模型,或压缩现有模型)
- 如何加速边缘推断以提供实时响应
For the problem of how to make models applicable for the edge environment, researchers mainly focus on two research directions: design new models/algorithms that have less requirements on the hardware, naturally suitable for edge environments, and compress existing models to reduce unnecessary operation during inference. For the first direction, there are two ways to design new models: let machines themselves design optimal models, i.e., architecture search; and human-invented architectures with the application of depth-wise separable convolution and group convolution.
对于如何使模型适用于边缘环境的问题,研究者主要集中在两个研究方向:设计对硬件要求较少、自然适用于边缘环境的新模型/算法,压缩现有模型以减少推理时不必要的操作。对于第一个方向,设计新模型有两种方式:让机器自己设计最优模型,即架构搜索;和群卷积的人类发明的体系结构。
For the second direction, i.e., model compression, researchers focus on compressing existing models to obtain thinner and smaller models, which are more computation- and energy-efficient with negligible or even no loss on accuracy. There are five commonly used approaches on model compression: low-rank approximation, knowledge distillation, compact layer design, network pruning, and parameter quantisation.
对于第二个方向,即模型压缩,研究人员专注于压缩现有模型,以获得更薄、更小的模型,这些模型更具计算和能源效率,精度损失可以忽略甚至没有。有五种常用的模型压缩方法:低秩近似,知识蒸馏,紧凑层设计,网络剪枝,以及参数量化。
Similar to edge training, edge devices and servers are not as powerful as centralised servers or computing clusters. Hence, edge inference is much slower. Some literature focuses on solving this problem by accelerating edge inference. There are two commonly used acceleration approaches: hardware acceleration and software acceleration. Literature on hardware acceleration mainly focuses on the parallel computing which is available as hardware on devices, e.g., CPU, GPU, and DSP. Literature on software acceleration focus on optimising resource management, pipeline design, and compilers, based on compressed models.
与边缘训练类似,边缘设备和服务器不如集中式服务器或计算集群强大。因此,边缘推断要慢得多。一些文献集中于通过加速边缘推断来解决这个问题。有两种常用的加速方法:硬件加速和软件加速。关于硬件加速的文献主要集中在并行计算上,并行计算可作为设备上的硬件,例如中央处理器、图形处理器和数字信号处理器。关于软件加速的文献侧重于基于压缩模型优化资源管理、流水线设计和编译器。
D. Edge Offloading
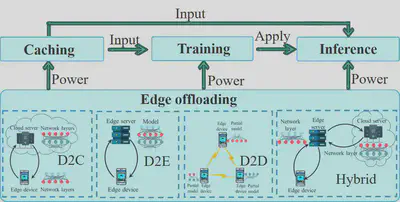
As a necessary component of edge intelligence, edge offloading refers to a distributed computing paradigm, which provides computing service for edge caching, edge training, and edge inference. If a single edge device does not have enough resource for a specific edge intelligence application, it could offload application tasks to edge servers or other edge devices.
Edge offloading layer transparently provides computing services for the other three components of edge intelligence. In edge offloading, Offloading strategy is of utmost importance, which should give full play to the available resources in edge environment.
作为边缘智能的必要组成部分,边缘卸载是指一种分布式计算模式,它为边缘缓存、边缘训练和边缘推理提供计算服务。如果单个边缘设备没有足够的资源用于特定的边缘智能应用程序,它可能会将应用程序任务转移到边缘服务器或其他边缘设备。
边缘卸载层透明地为边缘智能的其他三个组件提供计算服务。在边缘卸载中,卸载策略至关重要,它应该充分发挥边缘环境中的可用资源。
Available computing resources are distributed in cloud servers, edge servers, and edge devices. Correspondingly, existing literature mainly focuses on four strategies: device-to-cloud (D2C) offloading, device-to-edge server (D2E) offloading, device-to-device (D2D) offloading, and hybrid offloading. Works on the D2C offloading strategy prefer to leave pre-processing tasks on edge devices and offload the rest of the tasks to a cloud server, which could significantly reduce the amount of uploaded data and latency. Works on D2E offloading strategy, also adopt such operation, which could further reduce latency and the dependency on cellular network. Most works on D2D offloading strategy focus on smart home scenarios, where IoT devices, smartwatches and smartphones collaboratively perform training/inference tasks. Hybrid offloading schemes have the strongest ability of adaptiveness, which makes the most of all the available resources.
可用的计算资源分布在云服务器、边缘服务器和边缘设备中。相应地,现有文献主要关注四种策略:
- D2C:边缘设备卸载到云服务器
- D2E:边缘设备卸载到边缘服务器
- D2D:边缘设备卸载到边缘设备
- hybrid offloading:混合卸载
E. Summary
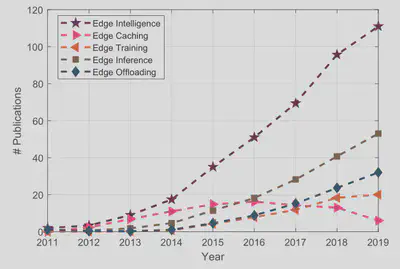
In our survey, we identify four key components of edge intelligence, i.e. edge caching, edge training, edge inference, and edge offloading. Edge intelligence shows an explosive developing trend with a huge amount of researcher have been carried out to investigate and realise edge intelligence over the past five years. We count the publication volume of edge intelligence.
在我们的调研中,我们确定了边缘智能的四个关键组成部分,即边缘缓存、边缘训练、边缘推理和边缘卸载。边缘智能呈现出爆炸式的发展趋势,在过去的五年中,大量的研究者被用来研究和实现边缘智能。我们统计了边缘智能的发布量,如图7所示。
Such prosperity of this research filed owes to the following three reasons.
First, it is the booming development of intelligent techniques, e.g., deep learning and machine learning techniques that provides a theoretical foundation for the implementation of edge intelligence.
Second, the increasing big data distributed at the edge, which fuels the performance of edge intelligence.
Third, the maturing of edge computing systems, and peoples’ increasing demand on smart life facilitate the implementation of edge intelligence.
作者认为,这一研究领域的繁荣有以下三个原因:
- 智能技术的蓬勃发展,例如深度学习和机器学习技术,为边缘智能的实现提供了理论基础。
- 分布在边缘的大数据越来越多,这推动了边缘智能的性能。
- 边缘计算系统的成熟,以及人们对智能生活需求的增加,促进了边缘智能的实现。
Session 则是对 Overview 的扩充,因此我在这里只写每个 Session 的标题。未来如有详细了解的需要,会继续进行补充。
III. Edge Caching
A. Preliminary of Caching
B. Cache Deployment
C. Cache Replacement
IV. Edge Training
A. Training Architecture
B. Training Acceleration
C. Training Optimisation
D. Uncertainty Estimates
E. Applications
V. Edge Inference
A. Model Design
B. Model Compression
C. Inference Acceleration
VI. Edge Offloading
A. D2C Offloading Strategy
B. D2E Offloading Strategy
C. D2D Offloading Strategy
D. Hybrid Offloading
E. Applications
VII. Future Directions and Open Challenges
A. Data Scarcity at Edge
B. Data Consistency on Edge Devices
C. Bad Adaptability of Statically Trained Model
D. Privacy and Security Issues
E. Incentive Mechanism
VIII. Conclusions
Bowen Zhou
Student pursuing a PhD degree of Computer Science and Technology
My research interests include Edge Computing and Edge Intelligence.